介绍
本章的内容重点是学习爬取动态网页。之前爬取的网站是静态的网页,内容都在html的代码中,直接分析提取即可。然而现在不少的网站是动态的,其爬取会更复杂一些。下面是百度百科对动态网页的解释。

简单的说,动态网页是先发送请求获取没有实际我们想要的内容的一个网站的空的基本的框架,再通过后续请求往这个空的框架里填充各种数据和内容,网页需要更新内容时,只需要请求需要更新的具体内容,然后把需要更新的网站的部分替换掉,这样就不需要重新加载整个网页,其内容是可以随着时间变化的。所以之前静态网页的方法只能获得一个空的框架,得不到想要的数据。
对于动态网站的爬取主要可以通过两种方法实现:
- 利用浏览器的开发者工具分析网站,寻找与需要爬取的目标数据对应的隐藏
URL,headers等数据,借助requests模块实现请求,进而爬取到数据。 - 利用模块
selenium模拟浏览器行为,即模拟键盘输入、点击、滑动页面等行为,获得网页完成所有请求后的源代码,再利用静态网页的方法进行后续的处理。
我们学习的重点是第一种方法,学会分析网站可以更高效的实现动态网站的爬取。第二种方法较为麻烦,不如第一种需要学习新的模块,而且还有使用指定的浏览器,下载合适版本的驱动,还需要将内容从源代码里提取出来,而使用第一种方法会发现,往往不需要专门去提取数据,所以第二种方法就不再详细叙述。
动态网页的爬取需要积累经验,一个小的细节就决定了程序是否能实现,所以希望读者能去实战各种网页,积累更多的经验,来应对各种各样的网站。
实例:腾讯天气数据
动态网页的爬取以爬取腾讯天气数据的实例来讲解。
首先搜索腾讯天气,在浏览器里进入腾讯天气的网站 https://tianqi.qq.com/ ,并打开开发者工具,选择Network,重新加载网页(见下图)。
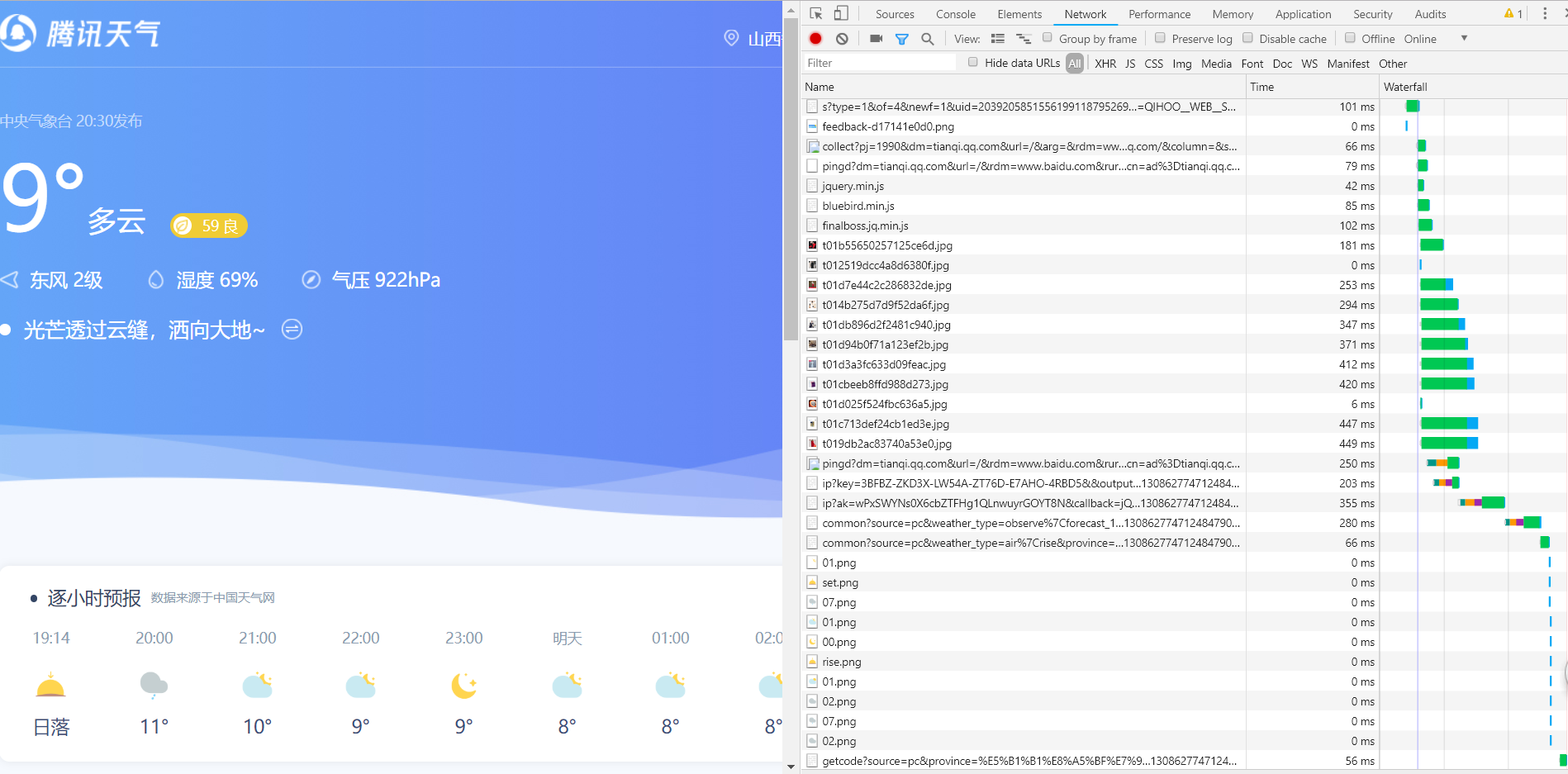
一般动态网页的后续数据加载的方式为XHR或者JS,有时也可能是Doc。就是图中分类的前两项和第七项。使用谷歌浏览器的开发者工具时如果遇到XHR会有暂停,而这个网站没有出现暂停,所以可以得知后续数据的请求是通过JS实现的。所以选择JS来寻找。
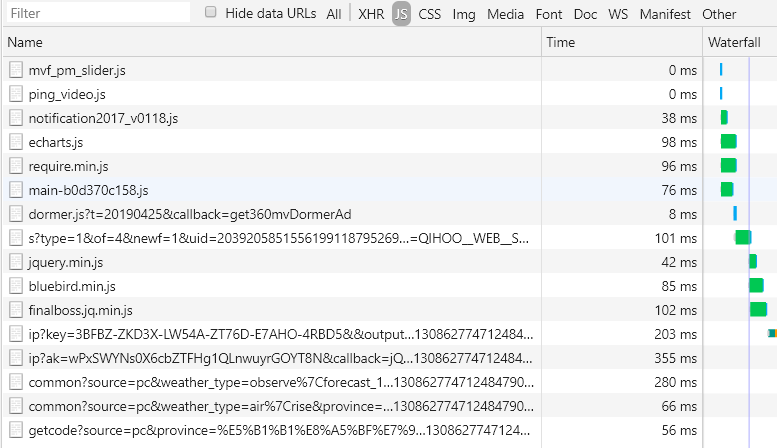
然后要做的就是从这些JS请求中找到请求天气数据的请求。
这里要用到一条经验,名字是.js结尾的可以不用看,因为这种文件是网站用来请求JavaScript的代码,是不会有我们需要的数据的。
排除掉.js文件后,先点击一个文件,点击选择右侧的Preview,然后继续点击浏览一遍剩余的文件的内容,找出目标数据文件即可。
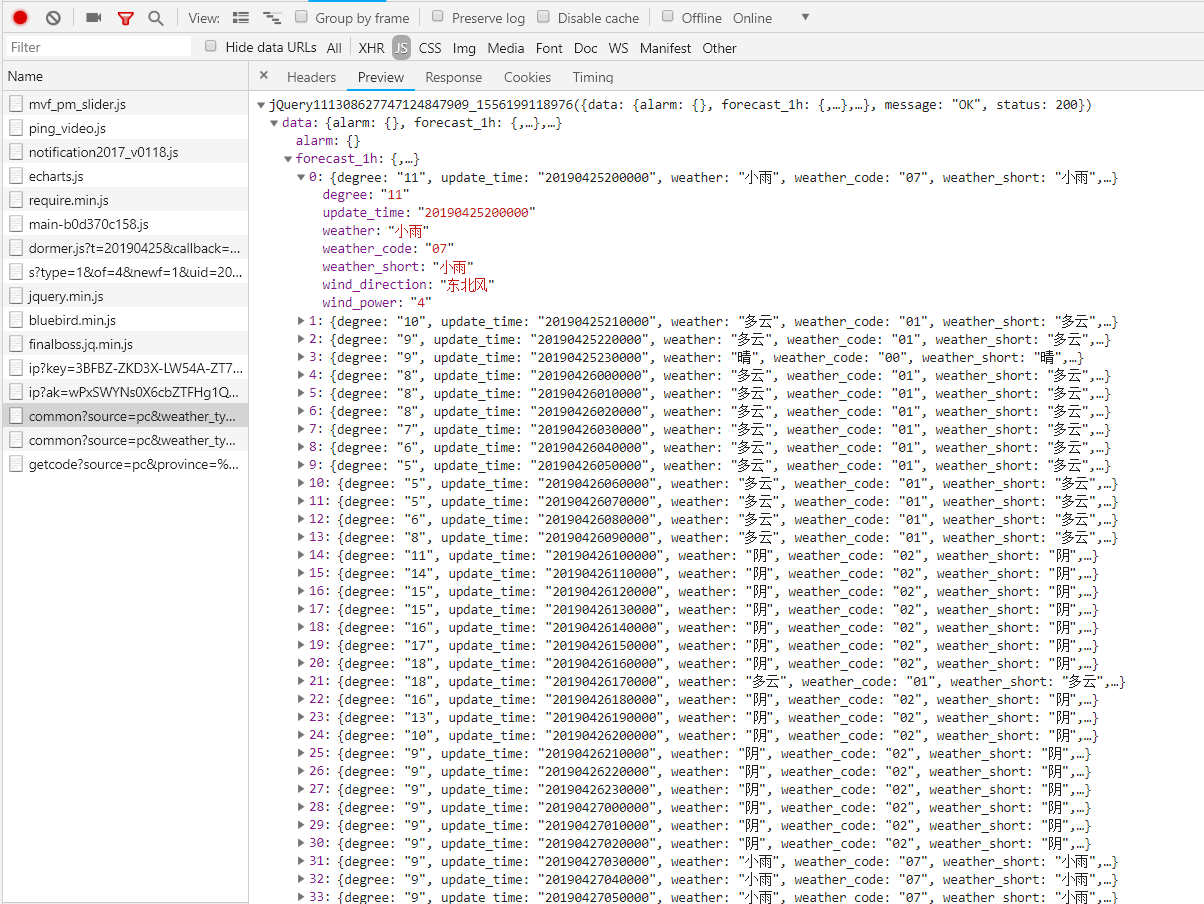
最后找到了目标文件(如上图所示),请求返回的内容是一个天气数据的一个列表,之后需要做的就是利用这一请求的信息(见下图)来实现一个爬虫,来爬取天气数据,返回一个便于操作的字典数据即可。
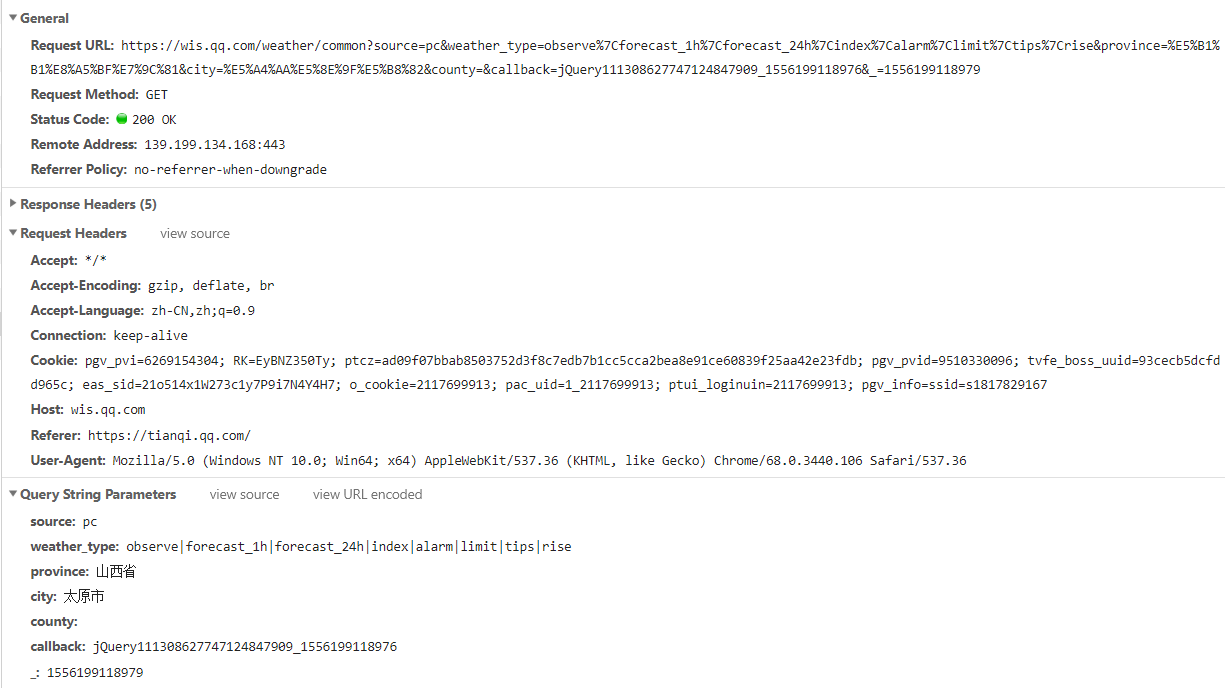
重点看一下参数部分:source应该就是请求源,值为PC。weather_type为请求的天气数据类型,比如forecast_1h是逐小时数据,forecast_24h是每天的数据,alarm是一些天气预警等。province就是数据对应位置的省,city就是对应的地级市,county就是对应的县级市,这个就根据需求改变即可。callback的内容就涉及了一个小技巧,我们一般会删去它,它的值就对应了这个请求的响应内容中开头部分,一般为jquery加上一串数字,删去它的值就使得响应只是一个字典格式的字符串,没有了jquery那些多余的东西,我们就可以直接用eval函数将返回的字符串转换成python的字典数据了。
_的值是一个叫做时间戳的数据,用来标识请求的时间,这个可以通过time模块中的time函数来调用获取。
分析完请求的参数就可以通过代码来实现这个程序了。

这一部分是首先引入必要的模块:requests和time。Location是一个用来储存URL部分参数的字典,Time是储存运行程序时的时间戳。

只够根据需求更改URL的参数的值。
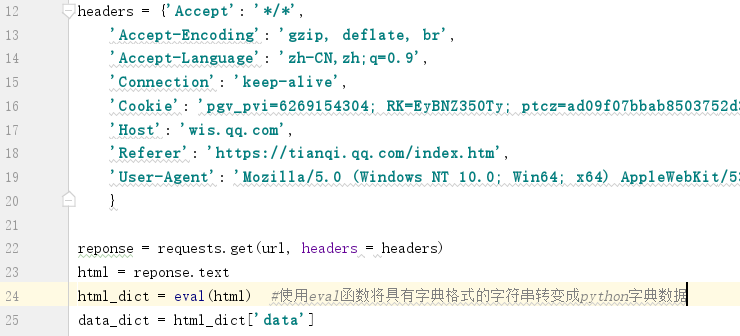
headers是表头的数据,用requests的get函数进行请求,html里是响应的text文本,是一个字典格式的字符串,直接用eval函数将字符串转化成python的字典数据,然后直接用python字典数据的知识提取需要的数据就可以。这样一个简单的动态网页的爬虫就完成了。
这个程序完整的源代码为:

对于这个例子来说,我们不用再分析网页源代码,唯一稍费功夫的地方就是去找到那个隐藏的请求的信息,这个方法就需要读者多去练习,提高分析网页请求的能力。
练习任务:
- 尝试爬取豆瓣喜剧的排行榜数据。
- 尝试在百度图片里爬取python相关的图片。
迁移拓展
完成一个爬虫的思路主要为:

各种爬虫基本上都是在这四步的基础上进行扩展,比如动态网页就是在第一步获取请求信息中,充分运用开发者工具分析找出关键的隐藏请求,之后的处理基本就与
静态的爬虫流程无异。所以,当读者想要实现一些特殊爬虫的时候,就是基于这四步,更改这四步中某几步的细节或方法来迁移性地实现新的类型的爬虫,下面就举几个例子来详细叙述一些。
QQ空间动态爬取
QQ空间的好友动态爬取是属于动态网站的爬取。
首先,第一步是获取请求的信息,在浏览器上登录你的QQ空间,然后打开开发者工具,然后刷新空间里的动态,然后尝试找到获取动态请求的请求,第一步就完成了。
第二步就是根据第一步获得的信息来进行代码实现,这里有一点需要注意,你想拿到的是你QQ好友的动态,所以发送的请求里要有你的账号信息才行,而这一些标识你身份的信息,比如你的账号和密码,都已经隐藏在cookie里,所以说,一般headers里的参数要填全,虽然可能有些参数不填不影响请求,但这需要你分析出那些是不必要的参数,所以说,为了省事还是填全为好。
第三、四步就是处理响应内容,这个请求的响应内容一般是一个xml文件,合理解码处理后可以获得一个具有HTML格式的字符串,可以直接用Beautifulsoup模块处理或正则表达式等,这里注意一点,一些没有在某个节点下的文本会被beautifulsoup模块直接放到一个
标签下,所以响应下的字符串里即使不全是html格式的字符串也可以直接输入给beautifulsoup函数。
手机app的爬虫
对于app的爬虫和常见的动态爬虫主要的差别也就出现在第一步,也就是如何获得请求信息。我们知道,依赖网络的app本质上也是一次次的隐藏起来的请求,动态网页我们有开发者工具这种具有抓包功能的工具,它把各种带有请求数据的数据包抓住复制了一份供我们分析。所以为了实现app的爬虫只需要找到一个能过替代开发者工具的抓包工具,只要把请求的数据包抓取下来,有了请求的信息,剩下的就和动态网页的爬虫没有什么区别了。
常见的手机抓包工具有:fiddler,charles等
这类抓包工具的使用网上都有教程,这里就不赘述了。
比如fiddler教程:https://www.cnblogs.com/hzg1981/p/5610530.html
总结一下,基本上绝大部分爬虫基本都可以基于那四步实现,所以当遇到特殊的爬虫,可以根据那四步从其他的之前做过的爬虫中迁移性地想出适合特定的条件的爬虫,做到融会贯通,面对各式各样的网站都能应对自如。
练习:
- 实现QQ空间动态的爬虫
- 爬取斗鱼直播app每一个推荐分类下的排名前十的直播间的主播名称、房间号、观看人数、房间名称、排名等信息。
补充知识
最后再补充一些读者做爬虫时可能遇到的问题。
- 中文乱码:
- 使用代码reponse.encoding = reponse.apparent_encoding
- 请求头‘Accept-Encoding’中的br问题:
去除br或者用brotl包解码
https://www.jianshu.com/p/70c3994efcd8?utm_source=oschina-app
- 有些网站不能频繁请求,可以通过设置时间间隔解决,代码为:time.sleep(1)。
- 有的网站会有反爬机制,同一个ip发送请求过多会被封ip,这时可以使用代理 ip,即使用requests.get的proxies参数。
获取免费代理ip的网站:https://www.xicidaili.com/
requests设置代理ip的方法:https://www.cnblogs.com/z-x-y/p/9355223.html

